
If we were to personify ChatGPT as a highly skilled and knowledgeable colleague, then a prompt would be the instruction you give. The more detailed and context-rich the instruction, the clearer the output definition, the better the result.
Due to the strong correlation between prompts and output, the market values prompts highly. Some speculators sell prompt bundles through advertisements, while others trade prompts on marketplaces like Promptbase. The most popular approach is to wrap high-quality prompts with a UI layer, turning them into SaaS products (e.g., Jasper, CopyAI). Essentially, these companies rent out prompts to derive value, except for those with unique data or large models of their own.
I think Prompts are not merely commodities to be rented or sold. Instead, like short videos and code, they should be shared and discussed in a UGC community.
The widespread adoption of ChatGPT has seen a substantial rise in the value and importance attributed to prompts. This surge can be credited to influencers who have generously shared an array of creative and free prompts, inspiring more users to join in the prompt creation. Consequently, a considerable number of Jasper users have transitioned to ChatGPT, finding value in freely available prompts despite their relatively lower quality. Looking ahead, it seems unlikely that users will opt to pay for prompts, given the abundance of freely accessible options.
In contrast to traditional coding methods that use abstract, structured statements for data manipulation, prompts employ natural language to achieve similar ends. The current product development process is often plagued by inefficient communication and a loss of critical information during translation from user needs to features implemented by developers. Prompts have the potential to mitigate this inefficiency by empowering users to describe their problems and the necessary steps for resolution in natural language. This translates to a lower barrier to entry, greater capabilities, and wider applicability, setting the stage for a rapid expansion in prompt usage.
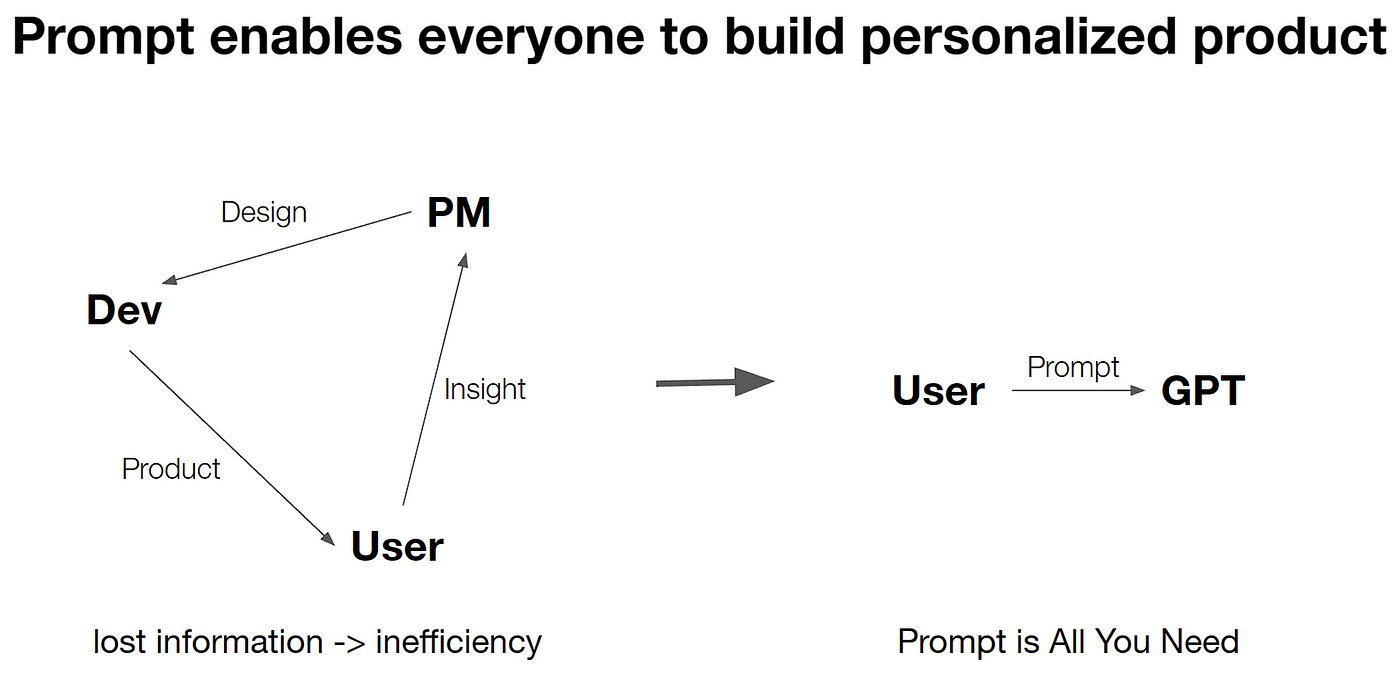
Before the advent of generative models, the creation of new content or applications necessitated a combination of innovative ideas, specialized skills, and considerable time investment. Today, with the power of generative models, anyone can wield expert-level skills. To bring an idea to life, users merely need to articulate it through a prompt, facilitating swift implementation and iteration. In this context, prompts have evolved to become conduits for translating imagination into reality.
However, there is an urgent need for a deeper understanding of the myriad use cases that large models can address. A solution might lie in the further exploration of prompt engineering, with the aim of unveiling the true potential of artificial intelligence and providing a platform for the manifestation of user imagination.
As prompts evolve, they are anticipated to grow more complex, emulating the progression seen in the history of coding languages. The advancement of large language models fosters an enhanced understanding of complex logic, thereby enabling the creation of more sophisticated prompts. Simultaneously, these improvements extend the capabilities of prompts and broaden the range of problems they can solve.
In addition to this, prompts represent a fundamental form of AI-native applications and usher in a novel form of content. The future of industry integration is likely to be heavily influenced by artificial intelligence, fusing traditional workflows with AI modules. This will pave the way for cost-effective solutions while enhancing efficiency.
Large corporations such as Bloomberg have started leveraging their unique proprietary data to train specialized large models. These models significantly outperform their generic counterparts in specific tasks. As the costs associated with training large models continue to plummet, the competitive focus will shift towards the acquisition of exclusive, proprietary data. This suggests that the future of AI will be dominated by those who can establish data monopolies.